생성형 AI를 사용하여 이미지 생성하기 2
stable-diffusion호스팅 업체도 찾았으니 이제 이미지를 생성할 차례이다.
캐릭터 이미지 생성하기
캐릭터 이미지는 image to image방식으로 생성하였다.
Stable diffusion의 control net에서 canny를 사용하여 스케치 기반의 이미지를 통해 주인공의 이미지를 생성하였다.
사용자 입력으로는 직접 그린 스케치 주인공의 스케치 이미지와 주인공의 외형적 특성에 관련한 키워드를 받는다. 입력받은 이미지와 키워드들로 stable diffusion을 사용하여 캐릭터 이미지를 생성하는 방식이다.


등장인물이 삽화에 등장해야 하기 때문에 캐릭터 이미지는 이후 생성되는 동화의 삽화에도 영향을 주어야 한다. 캐릭터가 이후 계속해서 생성 될 삽화에도 나타나야 하므로 삽화생성은 캐릭터의 이미지를 포함하여 생성되어야 한다.
삽화 내에서 캐릭터를 그릴 수 있는 방법은
1. image-to-image 방식을 사용하여 생성된 캐릭터에 배경을 생성하기
2. text-to-image를 사용하여 캐릭터 특징을 텍스트로 추출 후 프롬프트로만 생성하기
두가지의 방법을 생각할 수 있겠다.
결과적으로는 2번 방식을 사용하게 되었다
삽화 생성하기
동화의 삽화 생성시 중요한 요소는
- 얼마나 일관된 그림체로 생성되는가
- 주인공이 삽화에 잘 나타나는가 (사용자가 그린 캐릭터라고 생각이 들게 하는가)
- 현재 진행되고 있는 내용을 얼마나 잘 표현하는가
이 세가지를 기준으로 잡고 여러가지 시도를 해보았다.
방식1. stable-diffusion 사용하기
삽화 생성시 stable-diffusion을 사용한다면 lora를 적용해 일관된 그림체로 생성이 가능하다. 동화의 분위기에 맞는 그림체로 통일성 있게 만들어진다면 프로젝트의 완성도 또한 높아진다.

stable diffusion을 이용하여 text-to-image방식으로 삽화를 생성하는 방식은 다음과 같다

먼저 생성된 캐릭터의 이미지를 가지고 gpt-vision을 사용하여 외형을 텍스트로 추출한다.
gpt-vision 프롬프트
you're a helpful assistant who depict character's appearance.
depict with details only using only nouns and adjectives seperated by comma, so that can redraw it with keywords again.
depict with details using given description with only keywords seperated by comma without line break.
you must depict
- hairstyle
- top-
-pants
- shoes
- hair color and length
example : a boy with brown short hair, red shirt, blue shoes, brown pants if you cannot distinguish image return blank space이후 appearance_keyword라는 속성으로 캐릭터 엔티티에 추가하여 저장한다.
사용자가 입력한 동화 내용과, 현재 만들고 있는 동화 주인공의 엔티티에서 appearance_keyword 항목을 조합하여 gpt를 통해 stable-diffusion에 들어갈 프롬프트를 생성한다. 이후 생성된 프롬프트를 통해 삽화를 생성한다.
그러나 이 방식에는 여러가지 단점이 존재하는데...
느린 생성 속도
stable-diffusion 사용 시 평균적으로 20초 안팎의 생성 속도가 나왔다. 사용자 입력과 캐릭터 엔티티를 조합하여 gpt를 통해 prompt를 뽑아내는 전처리 과정이 필요하므로 총 걸리는 시간은 30초 ~ 1분 정도의 시간이 소요된다.
deformation
생성된 삽화 속 등장인물의 deformation 수준이 높았고 발생 빈도 또한 잦았다. 위의 예시에도 소의 형태가 일그러저 있음을 볼 수 있다.
텍스트 인식 성능
dall-e에 비해 stable-diffusion의 프롬프트 이해도가 훨씬 떨어진다. 특정 상황을 묘사하기에는 stable-diffusion의 텍스트 이해도가 떨어져 같은 구도의 밋밋한 삽화만 생성된다. 또한 구체적으로 시야각이나 구도를 제시해도 이를 따르지 않거나 이상한 이미지를 생성 하는 등의 결과를 보여주었다.
방식2. dall-e 와 stable-diffusion 같이 사용하기
stable-diffusion만을 사용한다면 text만으로 원하는 느낌의 이미지를 한번에 생성하기가 매우 어려웠다. 삽화는 현재 진행되고 있는 동화의 내용이 충실하게 표현되어있어야 하나 stable-diffusion 의 text-to-image로는 한계가 있다고 판단하였다.
이 방식은 먼저 DALL-E로 삽화으 스케치를 한 다음 stable-diffusion에서 canny를 통해 이미지를 생성한다.
단계1. 프롬프트 추츨
system prompt
you're a helpful assistant that depict details to generate image.
using given json, depict "currentContext" scene.
you should follow
- depict current scene in "mainCharacter"'s perspect of view
- do not contain any information of "mainCharacter"
- depict info must follow one of these format
[character] is [character's posture], in [background], [lights]
[object] is in [background], [lights]
- answer must be in english
input
{
"previousContext" : "순용이는 오두막을 발견했습니다. 오두막은 어두웠고 거기에는 곰이 살고 있었습니다.곰은 말했습니다. "안녕?" 순용이는 곰에게 꿀을 나누어주었습니다",
"currentContext" : "곰은 꿀을 맛있게 먹었습니다.",
"whereStoryBegins" : "오두막",
"mainCharacterName" :"순용"
}
output
The bear is sitting and eating honey, in a dimly lit cabin.
단계2. 스케치 생성하기
DALLE-3 로 흑백 스케치 이미지를 생성한다.
흑백 스캐치는 stable diffusion에 canny 를 사용하기 위해 생성하며 이를 통해 stable diffusion의 프롬프트 이해도가 떨어지는 문제를 해결할 수 있다.
Original Prompt
The bear is sitting and eating honey, in a dimly lit cabin.
DALLE-3 의 revised_prompt
A full sized image in black and white line sketch style, depicting a bear comfortably seated inside a dimly lit, rustic log cabin, indulging in a sweet jar of honey. The interior ambiance of the cabin shows minimal light sources creating natural shadows and highlights, perfectly resulting in a calm and serene atmosphere.
단계3. stable diffusion에서 canny controlnet을 사용하여 변환

sketch → canny controlnet → image 의 단계를 거치는이유
stable diffusion의 텍스트 이해도는 높지 않다!
- 사용자가 입력한 동화 내용에서 이미지를 자연스럽게 추출해야 한다.
- dalle 의 텍스트 이해도가 stable diffusion보다 훨씬 높다 즉 다양한 구도의 이미지가 생성 가능해진다
- 또한 dall-e 프롬프트와 stable diffusion의 프롬프트를 동일하게 사용하여 관리를 편하게 할 수 있다.
즉 sketch + prompt로 보다 안정적인 lora 적용 이미지를 뽑아내는 것이 가능하다.

a bear is standing, bee is flying from the window, light from the window, in the cabin
위의 이미지는 dalle → stable diffusion을 거친 과정이고 (방식1.) 아래 이미지는 stable diffusion만을 거친 이미지이다. (방식2.) 아래의 과정에서 각 guidance scale을 7.5, 12 를 주고 이미지를 생성했다.
이렇든 sketch → controlnet canny → image 라는 단계를 거치면 보다 간단한 프롬프트로도 lora가 적용된 보다 높은 수준의 이미지가 생성 가능하다.
그러나 이 방식도 결국 사용하지 않았다....
왜??
복잡한 파이프라인
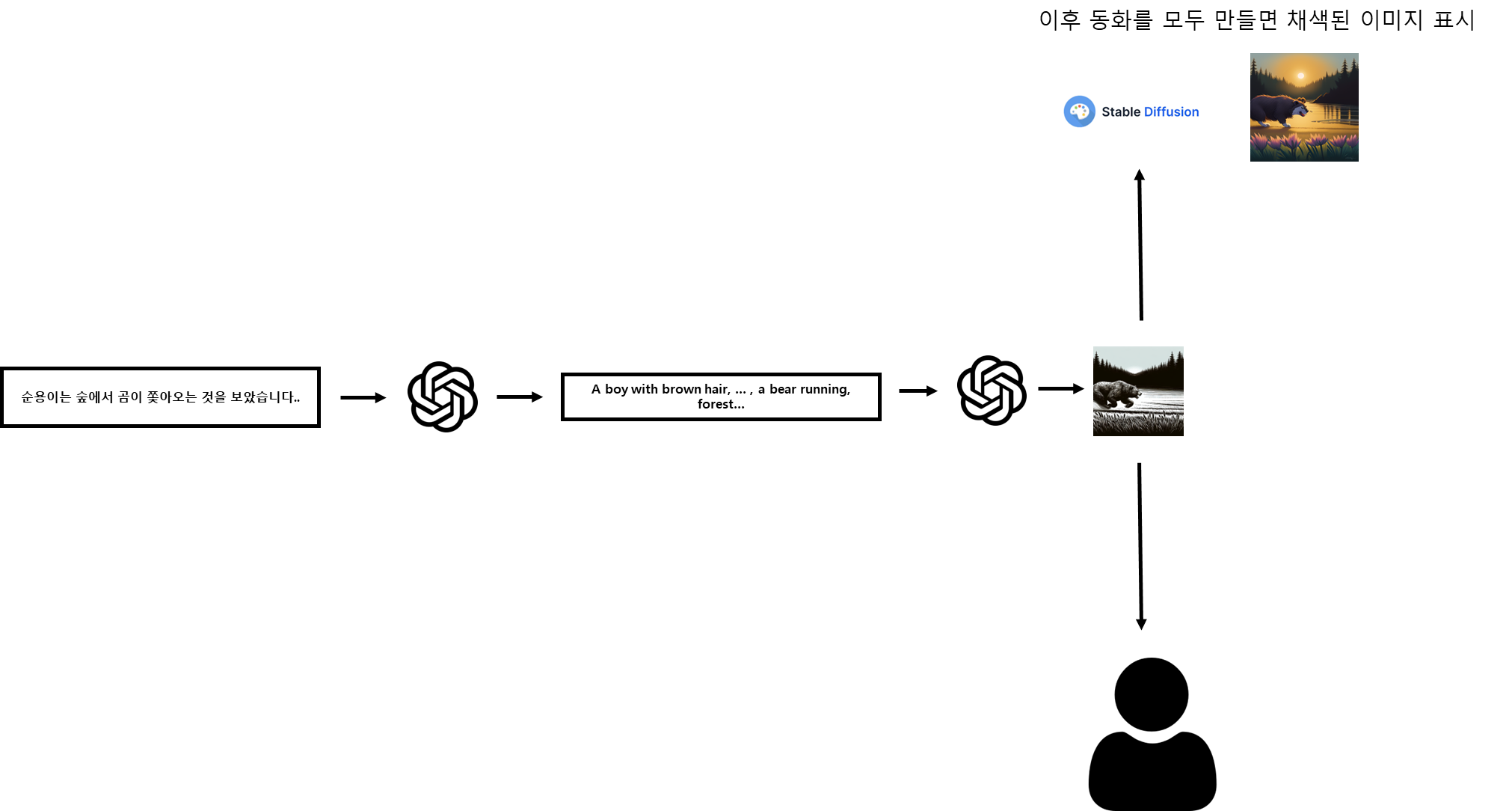
이 방식에서는 하나의 이미지를 생성하기 위해 생성형 AI를 3번이나 사용해야 한다. 채색된 이미지를 생성하기까지 거의 1분이 넘는 시간이 소요되기에 동화를 만드는 과정에는 스케치된 이미지만 보여준 후 동화를 완성하면 채색된 이미지를 보여준다.
이러한 구조는 복잡하고 유지 보수 측면에서도 상당히 별로였다. 무엇보다 생성형 AI를 사용하는 과정에서 어느 한 단계라도 문제가 생기면 다시 모든 과정을 반복해야 했다.
해결하지 못한 deformation
밑그림을 그리고 stable-diffusion으로 이미지를 생성하여도 deformation문제를 완전히 해결할 수는 없었다.
주인공의 등장
가장 큰 문제였다. 스케치를 이용하여 이미지를 생성하는 방식에서 주인공 캐릭터를 배경에 자연스럽게 집어 넣기 불가능하였다.
실시간으로 사용자 입력을 통해 삽화를 생성해야 하기 때문에 이미지를 수정하고 캐릭터 이미지를 집어넣어 생성하고 하는 과정을 사용할 수 없었다. 현재 삽화 생성 시간도 굉장히 느린데 더 복잡한 과정을 거칠 수는 없었다.
결국 방식2. 또한 다시 생각하게 되었고 결과적으로는 다른 방법을 통해 삽화를 생성하였다.
방식3. dall-e 사용하기
결국 실시간으로 상호작용하는 과정에서 생성속도가 무엇보다 중요했기에 dall-e만을 사용하여 삽화를 생성하게 되었다. 돌고 돌아 다시 dall-e만을 사용하기로 결정했다. 이 방식은 방식1. 과 거의 동일하난 stable-diffusion이 아닌 dall-e-3를 통해 삽화를 생성한다.

private static final ChatMessage SYSTEM_MESSAGE = new ChatMessage("system",
"""
you're a helpful assistant that depict details to generate image.
using given json, depict "currentContext" scene.
- choose random format given below
[whole context of appearanceKeyword] is [what main character is doing], in [background], [lights]
[other character] is [what they're doing], in [background], [lights]
[object] is in [background], [lights]
[background], [lights]
- answer must be in english"""
);
그러나 주인공의 이미지를 appearance_keyword라는 텍스트를 통해 삽화에서 생성되어 주인공의 생김새가 조금씩 달라지는 형태로 생성된다.
어느정도의 이질감이 드는것은 사실이나 결국 속도와 안정성을 우선시하여 dall-e-3를 사용하게 되었다. 또한 stable-diffusion과의 퀄리티 차이도 크게 나지 않았다.
결국 dall-e-3를 사용하여 삽화를 생성하게 되었다.
가장 큰 문제점은...
1. 캐릭터 생성 시 appearance_keyword가 이상하게 입력되면 망함
2. 같은 appearance_keyword라도 주인공이 조금씩 다르게 그려짐
이 두가지이다.
프로젝트를 진행하며 위의 두 문제점을 완벽히 해결할 수는 없었으나 그나마 가장 안정적이고 확실한 방법이어서 dall-e-3를 사용하여 삽화를 생성하게 되었다.